
A prominent company in the MLM sector needed to incorporate a vast volume of data into an unbalanced binary genealogy tree. The goal was to add 2 million users to a MySQL DB, maintaining the structure’s integrity while ensuring smooth data migration, tree path rendering, and minimizing system resource consumption.
The Binary Tree was to represent an MLM system, where users are added in a hierarchical structure, with one “father” having a maximum of two “children” placed either to the left or right under him, along with the second tree; Sponsor Tree. A Sponsor Tree in MLM is a hierarchical structure that shows the relationships between a sponsor and their recruits, forming a network of downline members.

The data provided by the Client needed to be validated for:
It involved collaborating closely with the client to clean the data and address any missing values before constructing the tree structure and organizing the data into the required format for database migration.

With over 2 million users, the data size and the complexity of tree path calculations led to performance issues. The unbalanced nature of the tree further complicated the relationships, leading to additional memory and computational overhead.
Transferring to the database quickly and efficiently.
Objective: To ensure the dataset was valid, accurate, and properly structured for migration.
Approach: Using the Pandas library, multiple python scripts analyzed and validated the provided CSV file. This involved:
Once the data was validated, the next step was converting it into the appropriate format for migration to database, which involved mapping the dataset to multiple schemas such as:
CSV files containing data formatted according to each table’s schema were created using the Pandas library. This conversion ensured the data was properly prepared for migration into the target tables.
The unbalanced nature of the Binary Tree structure led to disproportionate depths for new users from the root node (Admin User), caused deeper nesting and complicated the tree path calculations.
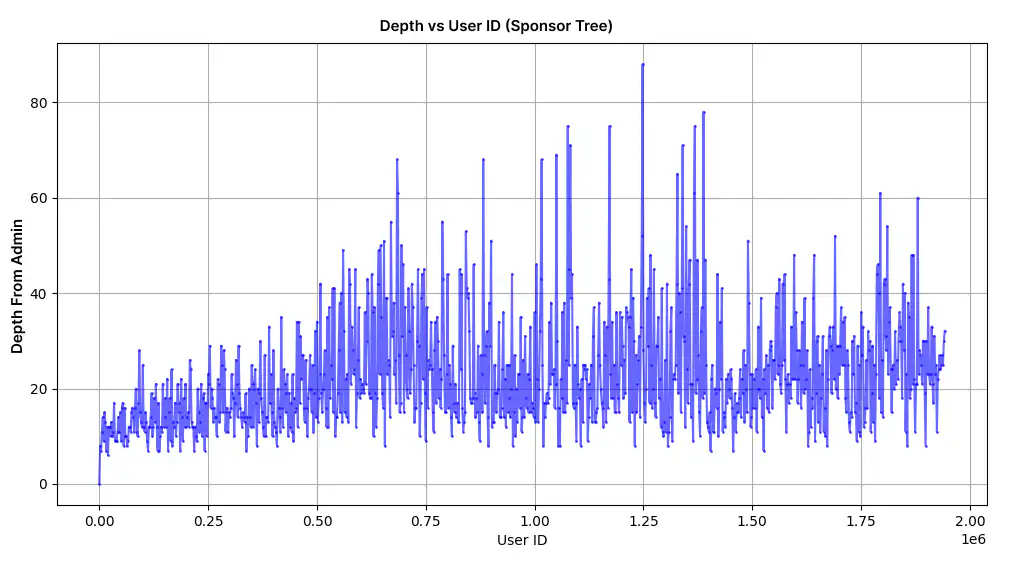
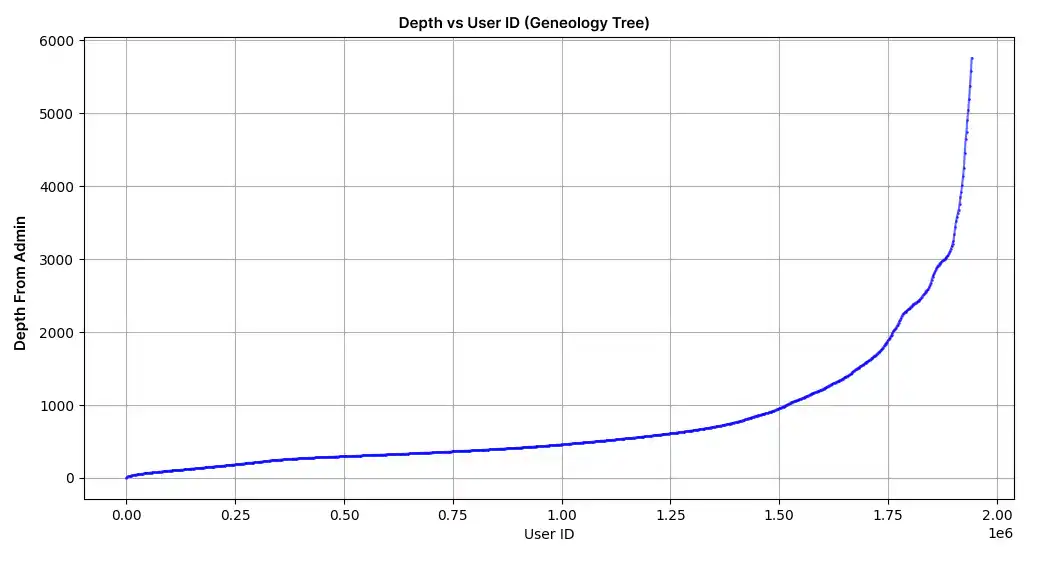
Developers explored Redis, an open-source, in-memory data store, to optimize performance. Redis offered high-speed data retrieval and storage capabilities, reducing the load on traditional disk-based systems. Its in-memory architecture enabled faster processing and minimized bottlenecks associated with reading and writing large datasets.
To handle the enormous dataset and efficiently process the data while making final adjustments and editing errors (such as duplication), our team incorporated Dask, a parallel computing library designed for big data processing. Dask allowed the team to process the large amounts of treepath data efficiently by converting treepath CSV files to parquet format for processing.
Objective: Efficient migration of 2 million users into the client database.
Approach: The migration of user data for 2 million users was carried out using the Pandas library to MySQL. The data, stored in CSV files formatted to match the user data table schemas, was successfully migrated in just 10 minutes.
Pandas proved insufficient for the large-scale migration of the treepath data, which consisted of almost 1.5 billion rows.
The team transitioned to direct file uploads from CSV to MySQL, removing Python/Pandas as the intermediary, and used the MySQL FILE UPLOAD command for the migration. This shift enabled faster and more reliable data migration, achieving 5 billion rows in just 30 minutes, with migration speeds up to 75 times faster compared to the previous approach.
With the data successfully processed, the foreign keys and indexes were added to the table for faster queries and datalook-ups. This enabled easy data access and ensured that the entire structure was fully operational.
Within just 15 days, our team successfully added 2 million users to the unbalanced MLM tree, overcoming significant technical challenges. The following outcomes were achieved:
The migration process was accelerated by 75 times, ensuring efficient handling of large-scale data.
The integration of Redis and Dask ensured that the system could scale effectively to handle 1.49 billion records and continue expanding.
The final approach reduced memory consumption and minimized downtime, allowing for quicker data access and tree rendering.
The migration was completed on time, with no major performance bottlenecks or data integrity issues.
This case study highlights the successful implementation of an advanced and scalable system for managing 2 million users in an unbalanced binary MLM genealogy tree. By using Redis, Dask, and MySQL, our development team overcame the challenges of large-scale data migration, unbalanced tree management, and system performance. The project not only met its deadline but also set a new standard for efficiently managing massive datasets in MLM structures. This accomplishment marks a significant milestone in Infinite MLM’s journey, ensuring that our system can support future growth without compromising performance.